")


What is CSRF
Cross-Site Request Forgery (CSRF) is one of the most common and dangerous web application vulnerabilities. In this article, we will learn how it works and how to fix it. We will discuss the different methods available to mitigate CSRF and their differences.
Didactic Scenario
Imagine the following scenario:
- You have a bank account with MoneyFriend;
- You regularly perform payments using the bank's website;
- One day you decide to check your account balance;
- You discover that your balance is $ 100;
- While still logged in on the bank's website (http://banco.com.br), you open a new tab and access http://malicioso.com.br (the Portuguese term for 'malicious');
- After http://malicioso.com.br finishes loading, you return to the bank tab and notice that your balance is now $ 70.
In this scenario, you were likely a victim of an attack that exploits the vulnerability known as Cross-Site Request Forgery (CSRF). Let's understand what happened behind the scenes, starting with the name of this vulnerability.
"Cross-Site Request Forgery" Meaning
"Cross-Site" means that a vulnerability is exploited between sites. In other words, it's possible to identify that at least two websites are involved in this attack. "Request Forgery" means that the request is forged or fake.
Combining all the terms, we can conclude that this vulnerability is a request forged by an attacker on one website (i.e., http://malicioso.com.br) to affect another site (i.e., the bank's website). The attacker forces the victim's browser to perform a request to the bank's website, as if the victim made the request themselves. In this case, this malicious request results in the missing $ 30 from your balance.
In more technical terms, we can say that this vulnerability is an exploitation of the server's trust in the client's browser. The server assumes that all browser requests are always sent by the user when they could actually originate from other websites (forged requests). In our example, the request was triggered by http://malicioso.com.br.
Diving into the technical realm
In this scenario, we can notice that $30 is missing from our account. The "missing amount" actually became a payment or a transfer for an individual or a company. Let's suppose that after examining our bank statement, we identified a $30 transfer to John Hacker.
Before understanding how this transfer happened, we need to understand how a legitimate transfer works. Let's check it step-by-step:
1) User signs into the bank website and gets a cookie containing the session identifier
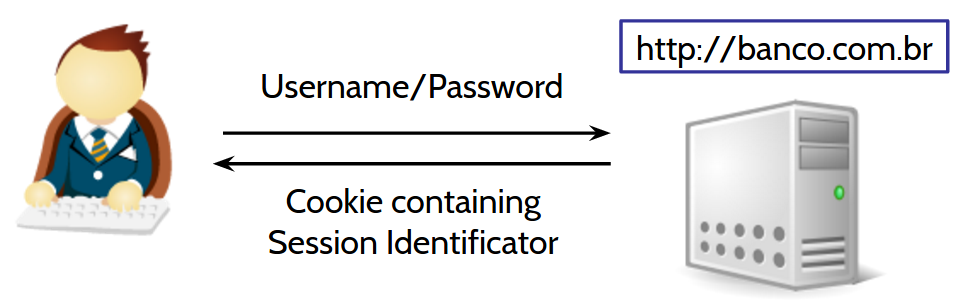
A little bit about the Session Identifier...
If multiple customers access the bank at the same time, how could the bank identify each of them? The bank gives a unique identifier to each customer, which is the session identifier. This identifier usually is composed of letters and numbers, e.g.,
1F9fNJIKSAGFj130imk013mVNH. This identifier usually is stored in a Cookie, which is a temporary file that can store low amounts of data and is managed by the customer's browser. This cookie is then passed along in all requests sent from the customers to the bank....Returning
2) User accesses/transfers and receives a form to fill
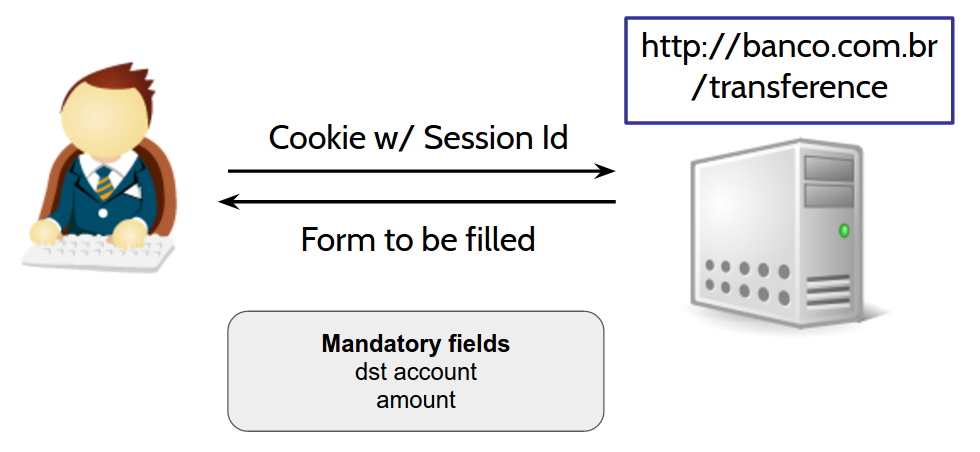
3) User sends the filled transfer form
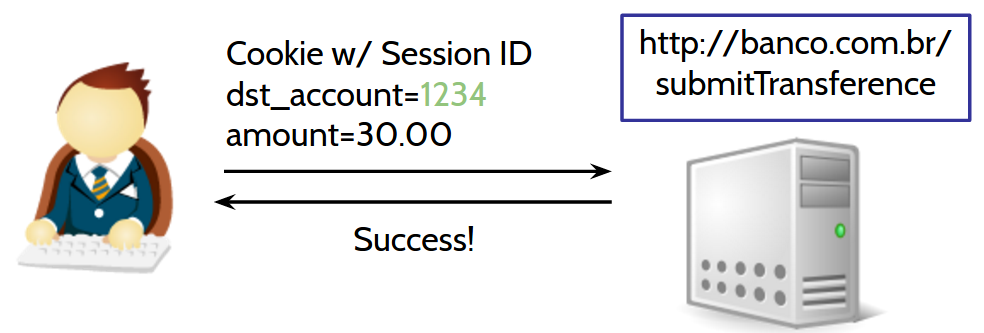
Ok, we understood how a legitimate transfer works. Now, thinking as an attacker, we need to develop a way to make the user's browser generate a transfer request, but specifying the attacker's account instead. This request would look like this:
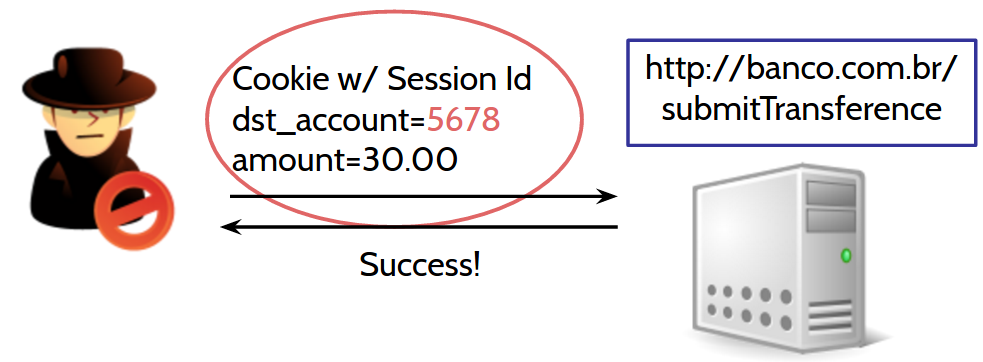
But we have a problem. How could we, as attackers, discover the session identifier value? That's the catch. We don't need to discover the session identifier, because whenever the victim's browser makes a request to the bank, it always embeds the bank's cookies, including the session cookie. Actually, it's more technically correct to say that the browser embeds all cookies related to that specific domain, i.e., banco.com.br.
We as attackers can't identify the session identifier inside the cookie but we don't need to. The browser will execute the malicious request that we've built, passing this session cookie for us. The browser actually doesn't know that it is being used as part of an attack. This "naiveness" by the browser is a problem known as "The Confused Deputy Problem" in computer science.
Developing our exploit
An "exploit" is the term used to denote programs that exploit vulnerabilities in an automated fashion. In other words, it means that we will develop a set of code to exploit Cross-Site Request Forgery automatically. As a side note, we can say that the website http://malicioso.com.br contains an exploit.
To create our exploit, we need to understand the ecosystem around it.
Note that so far we've understood the request that the victim's browser should send, but we haven't reached the practical part, i.e., how the browser will indeed create this request. Also note that this attack requires the victim's same browser to be used, as the session cookie varies from browser to browser. If the user logged into the bank using Internet Explorer and executed our exploit using Google Chrome, the attack wouldn't work.
See below the HTML code present on http://malicioso.com.br:
<html>
<body>
<img width="1" height="1" src="http://banco.com.br/submitTransference?dst_account=5678&amount=30.00" />
</body>
</html>
How strange! An "img" tag? Isn't this tag used solely to display images on a web page? In visualization terms, yes. However, in practice, what matters to us is that the browser created a (GET) request to the address "http://banco.com.br/transference?dst_account=5678&amount=30.00". We don't really care about the response. What matters is that the browser performs the request. If it works, we'll know by looking at the bank statement of our attacker's account (John Hacker's account).
The Big Picture
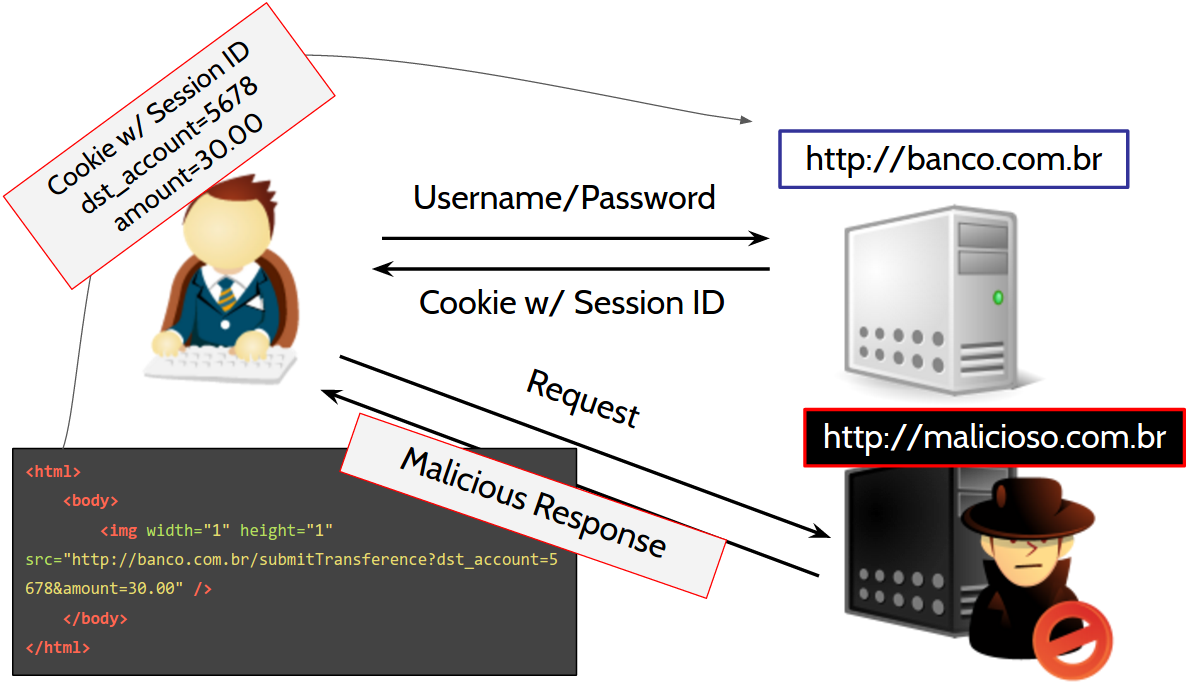
Common Questions
1) If the <img> tag performs only GET requests, we could just change the bank's transfer page to accept POST requests instead of GET. This way, all GET requests, including the one in this example, won't work. Right? Wrong! We would just need to change our exploit to work with POST requests. Check out the example below:
<html>
<!-- jQuery is a popular Javascript library -->
<!-- It eases the development, e.g., during -->
<!-- Ajax requests creation (our case) -->
<script src="jquery.min.js"></script>
<script>
$.ajax({
type: "POST",
url: "http://banco.com.br/submitTransference",
data: "dst_account=5678&amount=30.00"
});
</script>
</html>
2) But Cross-Origin Resource Sharing (CORS) will prevent this request from being triggered. Maybe. This answer is more complex and mandates a higher understanding of "Same-Origin Policy" and CORS. Let's go:
"Same-Origin Policy" Introduction...
Looking to protect web pages from accessing sensitive data from other web pages, the Same-Origin Policy was created, which is nothing more than a security policy implemented by each browser. This policy puts certain restrictions on how web pages from different origins (e.g., different domains like banco.com.br and malicioso.com.br) can interact.
However, in some cases, web pages from different origins want to interact fully and authorize each other. For such authorization to be recognized by the browser, it is necessary to use Cross-Origin Resource Sharing (CORS), which will be explained below:
CORS Introduction...
Cross-Origin Resource Sharing (CORS) was created to allow certain restrictions applied by the Same-Origin Policy using specific criteria.
When the browser detects a request from different origins, it first determines whether the request is secure to be sent.
To verify if the request is secure, it checks whether the request is using the methods GET, POST, or HEAD and whether there are no unusual headers, such as "X-JWT". If the request is configured differently than mentioned, the browser is forced to send a "Preflight Request".
A "Preflight Request" is a request that uses the OPTIONS method and includes some extra headers such as "Origin", "Access-Control-Request-Method", and "Access-Control-Request-Headers". It is forwarded to the server without a body. For example:
OPTIONS /resources/post-here/ HTTP/1.1 Host: bar.other User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 Connection: keep-alive Origin: http://foo.example Access-Control-Request-Method: POST Access-Control-Request-Headers: X-PINGOTHERThe server should respond by accepting the origin, the method, and the headers explicitly, using the headers "Access-Control-Allow-Origin", "Access-Control-Allow-Method", and "Access-Control-Allow-Headers". For example:
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 01:15:39 GMT Server: Apache/2.0.61 (Unix) Access-Control-Allow-Origin: http://foo.example Access-Control-Allow-Methods: POST, GET, OPTIONS Access-Control-Allow-Headers: X-PINGOTHER Access-Control-Max-Age: 86400 Vary: Accept-Encoding, Origin Content-Encoding: gzip Content-Length: 0 Keep-Alive: timeout=2, max=100 Connection: Keep-Alive Content-Type: text/plainAfterward, the browser understands that the request is secure to be sent and continues sending it, allowing the recently authorized origin to access the response headers and response data.
...Returning to the question
Of course, the bank won't allow malicioso.com.br because it would require a formal request from malicioso to the bank. That said, malicioso.com.br would then avoid at all costs requiring a "preflight request" from the browser.
It turns out that if the bank web pages themselves perform requests using unusual methods or unusual headers, the request triggered from the exploit won't work. It's common when the bank processes data using an Application Interface (API) that only accepts JSON content, forcing the browser to change the request content type to "application/json". This configuration triggers a non-secure request to the browser, thus requiring a "preflight request".
On the other hand, if the request is deemed secure, the exploit will successfully trigger the request but won't be able to get the response data. But as we've talked above, we don't care about the response. What matters is to trigger the request, thus CORS may or may not prevent CSRF attacks depending on how the bank's frontend requests access the bank's backend.
Mitigation
The essence of the attack is simple, but as we can see, there are many details that influence the attack and, consequently, the defense. We will explore some strategies that could be used to prevent CSRF exploitation. I can tell you in advance that these strategies are divided into measures to be taken by users and/or software developers.
Mitigation techniques for users
Remember the bank scenario? Well, if the user wasn't logged in, the attack wouldn't be possible, right? Yes, the attack wouldn't be possible because the user must be logged in for the attack to happen.
But that's not the only measure that a user could take. It's also possible to use plugins such as noScript, which tries to block malicious requests before they are executed. The problem is that usually noScript goes beyond what it should block and blocks many more requests, making the web browsing experience very bad. At least that was my impression in the past. Nevertheless, the idea that a plugin could interfere and identify requests between sites that could be malicious is interesting. Ideally, it would be absorbed by the browser, but it takes much more time.
Another approach would be to use different browsers. For example, you could have a habit of accessing your bank using one browser and using another browser for all other matters. This could be a good strategy to prevent CSRF attacks as well.
Mitigation techniques for developers
But seriously, we can't expect that all users will protect themselves, right? That's why we, as software developers, should always prevent CSRF attacks on our applications.
If we review the anatomy of a CSRF attack, we will note that the server can't distinguish whether the request is legitimate or forged. CSRF mitigation focuses on applying validation to the server, and there are multiple ways to do it.
Mitigation using Nonce
A Number Used Once (Nonce) is one way to prevent CSRF attacks. In short, it adds a validation step to the server before executing the desired operation (e.g., transferring an amount on banco.com.br).
The server sends a nonce code to the page containing the transfer form and expects to receive the same token. The secret of this control lies in the fact that the malicious website (malicioso.com.br) doesn't know the value of this token. Assuming that this token isn't easy to guess, of course. Because if the token is "123" and is always composed of 3 digits, we only need to try all possibilities [0-9][0-9][0-9] and quickly guess the token.
Notice that I've used the word "token" instead of nonce. I did that because nonce means that the nonce would be used only once, requiring the generation of another nonce for the next operation, whereas the token doesn't have this restriction.
If the user has a single token per session, that is enough. It's not necessary to generate a new token for each operation, although it is still interesting from a security point of view. Token maintenance becomes harder and could also affect the user experience between multiple tabs or devices. For example, during a bank transfer in one tab, if you're performing another operation in another tab, it could fail if the token isn't regenerated.
It's important to remember that the token must be unique per user, hard to guess, and generated using a secure Pseudorandom Number Generator (PRNG). Otherwise, it would be possible to guess the next token. And last but not least, none of the above matters if the server doesn't reject requests that don't contain the expected CSRF token.
Mitigation using Double Submit Cookies
Before we talk about "Double Submit Cookies" or "Triple Submit Cookies," we need to talk about how cookies work:
Cookies Introduction...
Cookies can be created by the browser using the JavaScript language or by the server by passing "Set-Cookie" headers in HTTP responses. In such a header, the server must provide the cookie name and value, but it can go beyond.
It's possible to add an HttpOnly flag, which makes a cookie unreadable from JavaScript instructions. This is very useful for cookies that only need to be present on HTTP requests, e.g., a session cookie. There's also the Secure flag, which restricts the cookie to be sent only in HTTPS connections. Cookies with this flag set won't be sent in HTTP connections.
Besides flags, it's also possible to specify the domain and path in which the cookie will be valid, e.g., /transference.
There's also the "SameSite" attribute, which is one of the mitigation strategies that will be covered in the next lines :)
Set-Cookie header example:
Set-Cookie: name=Anderson; domain=banco.com.br; path=/transference; Secure; HttpOnly...Returning to "Double Submit Cookies"
The idea behind Double Submit Cookies is to send a cookie with a random value and include a parameter in the request body containing the same random value. The server must then verify if the value passed in the cookie is the same as the value passed in the body parameter.
This approach is stateless because, unlike a Nonce/Token solution, the server doesn't need to know this random value beforehand. It's also efficient because the attacker can't read the value from the cookie to replicate it in the request body.
It could be further improved by tying the Session ID with the random value to ensure that it's not possible to bypass this control by sending random values, even if they are identical, in the cookie and the request body.
The problem is that if the attacker has access to any subdomain (legitimately or through Cross-Site Scripting (XSS) (in Portuguese)), for example, malicioso.banco.com.br, they can read cookies from banco.com.br. This way, the attacker would be able to read the cookie and use the same random value in the request body. Cookies can also be written through "Man-In-The-Middle" and "Man-In-The-Browser" attacks.
Given the weaknesses of this control mentioned above, another mitigation mechanism was suggested, called "Triple Submit Cookies". However, it is also likely to be circumvented. There's an interesting analysis here and a presentation here.
Mitigation using the "SameSite" Cookie attribute
Recently introduced by Google Chrome 51, the "SameSite" attribute informs the browser that cookies should only be sent from the origin that created them.
It ensures that all requests from "malicioso.com.br" to "banco.com.br" do not include any cookies! Ideally, all your cookies should have this attribute by default, just like they should have HttpOnly and Secure. They should only be disabled if there is a good reason to stop using them.
This protection applies only to requests considered 'secure' by the browser when it comes to CORS. Even GET requests would be protected.
It would be great if this protection were added to all cookies by default, but since it is new, if that happens, many websites would stop working on Google Chrome, and users would move to other browsers that don't have this control, such as Firefox. It could even result in the return of Internet Explorer ... just kidding.
Mitigation using alternate controls
There are other controls that are not tokens or a combination of cookies with parameters in the request body that can help prevent CSRF attacks:
- "Referer" header validation: Yes, it's simple, and it helps a lot. An attacker cannot modify the "Referer" header. One attempt at a CSRF attack will bring in the request the website that originated the request as "malicioso.com.br" instead of "banco.com.br".
- "Origin" header validation: Similar to the "Referer" validation above, but it's different. The Origin header was created to prevent attacks between different origins and is sent even in HTTP requests originated from HTTPS URLs.
- Adding a Captcha: As Captcha mitigates automated attacks, it also works to block CSRF attacks because the Captcha would need to be filled correctly.
Common Questions
1) I'm developing an API, and I've disabled CSRF protection from my framework to make the API work. Since I'm building an API, there is no problem, right? Wrong! This is a common misconception among developers. They underestimate the damage that can result from a CSRF attack. Even when developing an API, you could store the session identifier in a cookie or in localStorage (a private space for each domain to store more data than a cookie; it uses the "key => value" format and was introduced in HTML5 with a 5 MB limit) and pass it as an HTTP header. This is commonly done in the "Authorization" header, but you can use any other header, e.g., "X-JWT" (as a side note, headers that start with "X" indicate customized headers, in other words, headers that aren't part of the HTTP specification) to pass a JSON Web Token, for example. However, storing a session identifier in localStorage creates another vulnerability (see the next question #2 below).
A little bit more about localStorage...
LocalStorage was introduced in HTML5 and provides more space than cookies for applications to read and write arbitrary data without an expiration time. It works with keys and values. For example, an application could store the key "user" containing the following value:
{ id: 10, name: "Anderson Dadario", plan: { name: "Basic", price: { amount: 10, currency: "USD" } } }There are other storage options besides localStorage, such as sessionStorage, Indexed DB, Web SQL Database, etc., but they won't be discussed here.
2) I'm storing the session identifier in localStorage. Am I safe? Not yet. You can say that you're preventing CSRF because the browser only includes cookies and not values from localStorage, but on the other hand, you've introduced a new vulnerability in your application.
Your session identifier, which previously could be protected in a Cookie from JavaScript instructions using the "HttpOnly" flag, is now vulnerable to being read by JavaScript since that protection isn't available for localStorage. In other words, a Cross-Site Scripting (XSS) (in Portuguese) attack could access localStorage, retrieve the session identifier, and send it to the attacker's server, leading to account hijacking.
Conclusion
As you can see, the essence of CSRF (also known as XSRF) is simple, but there is a layer of complexity when it comes to more sophisticated attacks and defenses.
This attack can cause, and has caused, a lot of damage by impersonating user actions. It is often classified with high severity in penetration test reports.
If you enjoyed this article, please share it and subscribe to the list below to receive my future articles in your inbox. I will soon have more online courses that will include practical examples of CSRF attack and defense, not to mention other vulnerabilities.
That's all, folks!
Thank you, and stay tuned :)